

AI,人工智能,这个东西其实一旦都不新鲜。
从早些年的科幻作品,到后来的逐步落地,从1997年IBM超级电脑“深蓝”击败国际象棋大师卡斯帕罗夫,到2016年Google AlphaGo战胜围棋冠军李世石,AI一直都在进步,也一直在演化。
但因为算力算法、技术能力、应用场景等方面的种种限制,AI一直有些空中楼阁的感觉。
直到出现了ChatGPT,AI才真正引燃了普通人的热情,让我们发现,AI竟然如此强大,又如此唾手可得,让众多个体、企业为之兴奋,为之癫狂。

众所周知,足够强大与合理的硬件、算法,是实现高效、实用AI的两大基石,而在这一番AI热潮中,NVIDIA之所以春风得意,就得益于其在高性能计算领域多年来的布局和深耕,非常适合超大规模的云端AI开发。
当然,AI无论实现方式还是应用场景都是多种多样的,既有云侧的,也有端侧的。
NVIDIA的重点在云侧和生成式AI,Intel在云侧生成式、端侧判定式同时出击,而随着越来越多的AI跑在端侧,更贴近普通用户日常体验,所带来的提升越来越明显,Intel更是大有可为。
端侧AI有几个突出的特点:
一是用户规模庞大,应用场景也越来越广泛;
二是延迟很低,毕竟不需要依赖网络将指令、数据传到云侧处理再返回;
三是隐私安全,不用担心个人信息、商业机密等上传后泄露;
四是成本更低,不需要大规模服务器和计算,只需本地设备即可完成。

端侧AI,说起来大家可能会感觉很陌生,但其实,人们习以为常的背景模糊、视觉美颜、声音美化(音频降噪)、视频降噪、图像分割等等,都是端侧AI的典型应用场景,背后都是AI在努力。
这些应用要想获得更好的效果,就需要更完善、复杂的网络模型,对于算力的需求自然也在快速增长。
比如噪音抑制,算力需求已经是两年前的50倍,背景分割也增长了10倍以上。
更不要说生成式AI模型出现后,对算力的渴求更是飞跃式的,直接就是数量级的提升,无论是Stable Diffusion,还是语言类GTP,模型参数都是非常夸张的。
比如GPT3的参数量达到了1750亿左右,相比GPT2增加了几乎500倍,GPT4估计可达到万亿级别。
这些都对硬件、算法提出了更苛刻的要求。

Intel自然也早就开始关注并投入AI,无论是服务器级的至强,还是消费级的酷睿,都在以各种方式参与AI,“XX代智能酷睿处理器”的说法就在很大程度上源于AI。
在此之前,Intel AI方案主要是在CPU、GPU的架构、指令集层面进行加速。
比如从十代酷睿和二代可扩展至强加入的基于深度学习的DL Boost,包括VNNI向量神经网络指令、BF16/INT8加速等等。
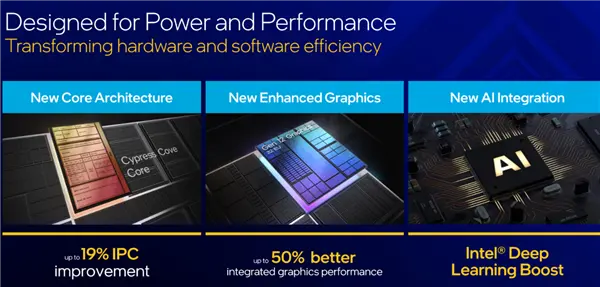
比如11代酷睿加入的高斯网络加速器GNA 2.0,相当于NPU的角色,只需消耗很低的资源,就能高效进行神经推理计算。
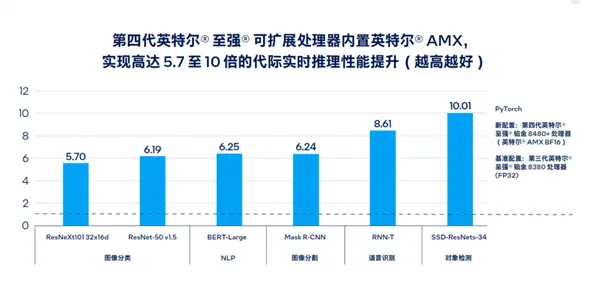
比如代号Sapphire Rapids的四代可扩展至强上的AMX高级矩阵扩展,使得AI实时推理和训练性能提升了多达10倍,大型语言模型处理速度提升了足有20倍,同时配套的软件和工具开发也更加完善丰富。
在Intel看来,没有单一的硬件架构适用于所有的AI场景,不同硬件各有特点,有的算力强大,有的延迟超低,有的全能,有的专攻。
AI作为基础设施也有各种各样的场景应用和需求,负载、延迟都各不相同,比如实时语音和图像处理不需要太强的算力,但是对延迟很敏感。
这时候,Intel XPU战略就有着相当针对性的特殊优势,其中CPU适合对延迟敏感的轻量级AI处理,GPU适合重负载、高并行的AI应用。
Intel另一个无可比拟的优势就是稳固、庞大的x86生态,无论应用还是开发,都有着广泛的群众基础。
现在,Intel又有了VPU。

将在今年晚些时候发布的Meteor Lake,会首次集成独立的VPU单元,而且是所有型号标配,可以更高效地执行特定AI运算。
Intel VPU单元的技术源头来自Intel 2017年收购的AI初创企业Movidius,其设计的VPU架构是革命性的,只需要1.5W功耗就能实现4TOPS的强大算力,能效比简直逆天,最早用于无人机避障等,如今又走入了处理器之中,与CPU、GPU协同发力。
VPU本质上是专为AI设计的一套新架构,可以高效地执行一些矩阵运算,尤为擅长稀疏化处理,其超低的功耗、超高的能效非常适合一些需要长期打开并执行的场景,比如视频会议的背景虚化、移除,比如流媒体的手势控制。
之所以在已经有了CPU、GPU的情况下,还要做一个VPU,Intel的出发点是如今很多端侧应用是在笔记本上进行,对于电池续航非常敏感,高能效的VPU用在移动端就恰如其分。
另一个因素是CPU、GPU作为通用计算平台,本身就任务繁重,再给它们增加大量AI负载,执行效率就会大打折扣。


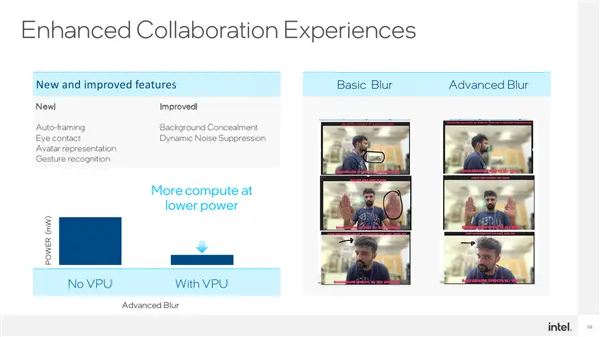
具体到应用场景,VPU也是非常广泛的,比如说视频会议,现在的CPU AI已经可以实现自动构图(Auto-Framing)、眼球跟踪、虚拟头像/人像、姿势识别等等。
加入低功耗、高算力的VPU之后,还可以强化背景模糊、动态降噪等处理,让效果更加精准,比如说背景中的物体该模糊的一律模糊、人手/头发等不该模糊的不再模糊。
有了高效的硬件、合适的场景,还需要同样高效的软件,才能释放全部实力、实现最佳效果,这对于拥有上万名软件研发人员的Intel来说,真不是事儿。
Meteor Lake还没有正式发布,Intel已经与众多生态伙伴在VPU方面展开了合作适配,独立软件开发商们也非常积极。
比如Adobe,很多滤镜、自动化处理、智能化抠图等,都可以用VPU来跑。
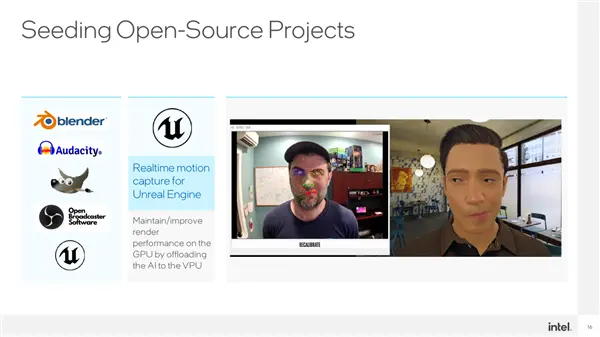
比如Unreal Engine虚幻引擎的数字人,比如虚拟主播,VPU都能很好地实时捕捉、渲染处理。
Blender、Audacity、OBS、GIMP……这个名单可以拉出很长一串,而且还在不断增加。

更重要的是,CPU、GPU、VPU并非各行其是,而是可以联合起来,充分发挥各自的优势,达到最好的AI体验效果。
比如说基于GIMP里就有一个基于Stable Diffusion的插件,可以大大降低普通用户使用生成式AI的门槛,它就能充分调动CPU、GPU、VPU各自的加速能力,把整个模型分散到不同IP之上,彼此配合,获得最好性能。
其中,VPU可以承载VNET模块运行,GPU用来负责编码器模块执行,通过这样的合作,生成一张复杂的图片也只需20秒左右。
在这其中,VPU的功耗是最低的,CPU次之,GPU则是最高的。

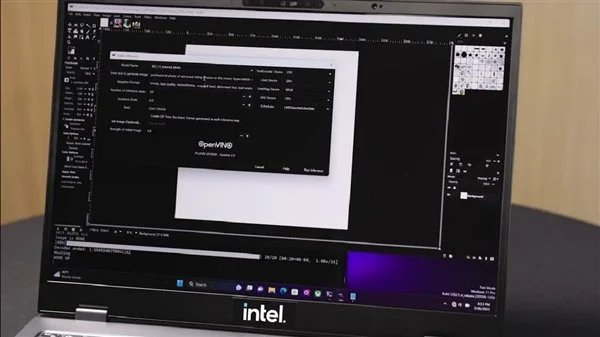
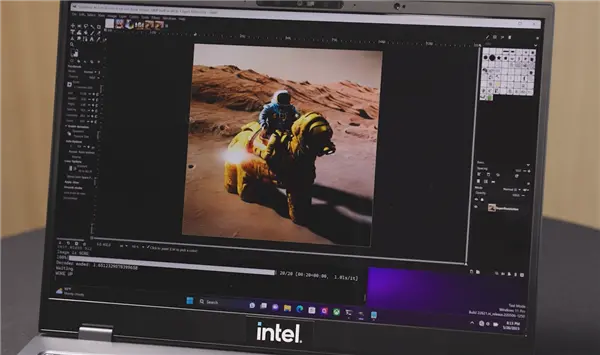
Intel已经充分意识到AI对于PC体验增强的重要性,而为了迎接这一挑战,Intel正在硬件、软件两个层面全力推进,对AI在的端侧的发展、普及打下坚实的基础。
硬件层面,CPU、GPU、VPU将组成无处不在的底层平台;软件层面,OpenVINO等各种标准化开发软件将大大推动应用场景的挖掘。
未来,搭载Meteor Lake平台的轻薄笔记本就可以轻松运行Stable Diffusion这种大模型来实现文生图,大大降低AI的应用门槛,无论判定式AI还是生成式AI都能高效执行,最终实现真正的AI无处不在。
涉及观点仅代表个人,与本站立场无关。本站不对内容的真实性及完整性作任何承诺。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫