关于 AI 绘画,你需要知道的一些事。


上周,备受期待的 Midjourney V5 AI 艺术生成器正式发布,再次改变了 AI 驱动的艺术创作世界。它拥有显著增强的图像质量、更多样化的输出、更广泛的风格范围,以及对无缝纹理的支持、更宽的宽高比、改进的图像提示、扩展的动态范围等。
下图是以“埃隆·马斯克介绍特斯拉,90 年代的商业广告”为 prompt(提示),分别用 Midjourney V4 和 Midjourney V5 生成的图像。

此次满足人们期待的是,Midjourney V5 带来了更逼真的图片生成效果,更有表现力的角度或场景概述,以及终于画对的“手”。曾经在 AI 绘画界广泛流传的一个笑话是,“永远不要问一个女人的年龄或一个 AI 模型为什么要把手藏起来。”
这是因为,AI 艺术生成器是“画手困难户”,尽管它们可以掌握视觉模式,但不能掌握潜在的生物逻辑。换句话说,AI 艺术生成器可以计算出手有手指,但很难知道一个人的一只手正常应该只有 5 个手指,或者这些手指之间应该具有固定关系的设定长度。
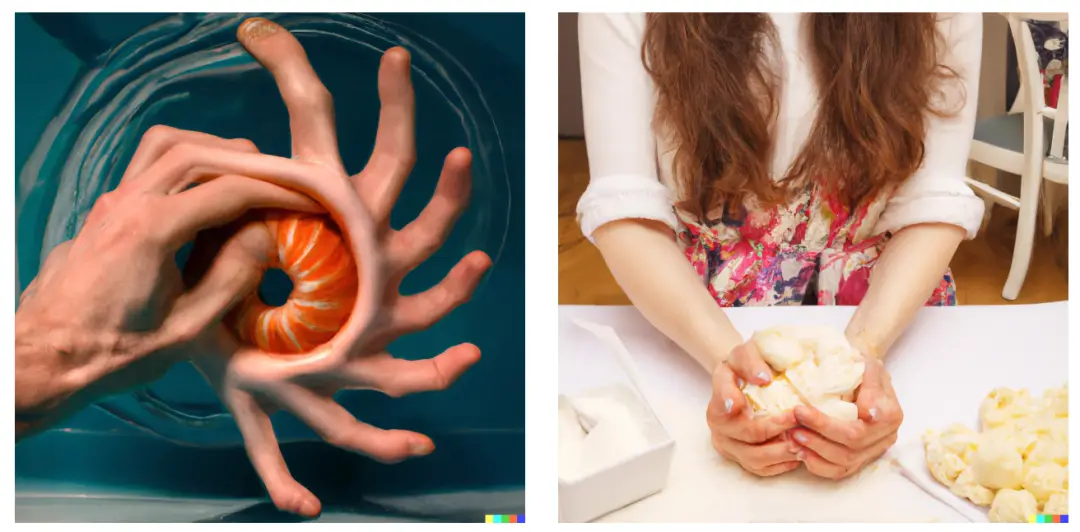
在过去的一年里,AI 艺术生成器无法正确渲染手的 “缺陷” 已经成为一种文化修辞。手部问题在一定程度上与 AI 艺术生成器从它们接受训练的大量图像数据集中推断信息的能力有关。
值得注意的是,Midjourney V5 可以很好地生成逼真的人手。大多时,手是正确的,一只手有 5 个手指,而不是 7-10 个。
Midjourney V5 的发布,引起了全球用户更广泛的兴趣激增,巨大流量的涌入使得 Midjourney 服务器短时间崩溃,进而导致众多用户无法访问。除此之外,OpenAI 的 DALL·E 2、Stability AI 的 Stable Diffusion 等 “文生图” 模型此前也是业内讨论的热门对象。
当人们向这些 “文生图” 模型中输入任何文本后,它们就可以生成与该描述相匹配的、较为准确的图片,生成的图片可以被设定为任意风格,如油画、CGI 渲染、照片等,在很多情况下,唯一的限制来自人类的想象力。
前世:一场从DeepDream开始的梦
2018 年,第一幅由 AI 生成的肖像《Edmond de Belamy》问世,它由生成对抗网络(GAN)创建,是 Obvious Art 的 “La Famille de Belamy” 系列的一部分,最终在佳士得艺术品拍卖会上以 432500 美元成交。
2022 年,Jason Allen 的 AI 创作作品《Théâtre D’opéra Spatial》在科罗拉多州博览会的年度艺术竞赛中获得了第一名。

近些年,各类 “文生图” 模型也在人们的期待中纷纷登场。当神经网络在图像处理方面取得了一定的成果后,研究人员们便开始开发一些可视化技术,以更好地了解这些神经网络是如何看待世界并进行分类的,由此塑造了一个又一个 “文生图” 模型。
DeepDream 根据神经网络学到的表征来生成图像,在获取输入图像后,通过反向运行经过训练的卷积神经网络(CNN),并试图通过应用梯度上升来最大化整个层的激活。下图(左)显示了原始输入图像及其 DeepDream 输出。

令人惊讶的是,输出图像中包含了许多动物的面部和眼睛,这是因为 DeepDream 使用了 ImageNet 数据库(不同犬种和鸟类的例子)来训练。对于一些人来说,DeepDream 生成的图像类似于梦境般的迷幻体验。但即便如此,DeepDream 加速了人们将 AI 作为艺术图像创作的工具的工作。
Neural Style Transfer 是一种基于深度学习的技术,能够将一张图像的内容与另一图像的风格相结合,如上图(右),将梵高的《星夜》应用于目标图像。Neural Style Transfer 重新定义了 CNN 中的损失函数来实现——通过 CNN 的高层激活保留目标图像,以及多层激活来捕捉其他图像的风格。由此,输出的图像将保留输入图像的风格与内容。
2017 年,Wei Ren Tan 等人提出了模型 “ArtGAN”,尽管其输出的图像看起来完全不像是画家的作品,但仍旧捕捉到了艺术品的低阶特征。由此,ArtGAN 激发了更多研究者使用 GAN 生成艺术图像的兴趣。

不久之后,Ahmed Elgammal 等人提出创造性对抗性神经网络 “CAN”,以训练 GAN 生成被鉴别者视为艺术但不符合任何现有艺术风格的图像。由 CAN 产生的图像看起来大多像一幅抽象画,给人一种独特的感觉。
2017 年,Phillip Isola 等人创建了条件型 GAN,即 pix2pix,接收输入图像后生成一个转换版本。例如,在现实生活中,假设有一个 RGB 图像,我们可以轻松将其转换为 BW (黑白二值图像)版本。但若想要把 BW 图像变成彩色图像,依靠手动上色就很耗时。pix2pix 则可以自动完成这一过程,并应用于任何图像对的数据集,而不需要调整训练过程或损失函数。

pix2pix 是生成式 AI 的一个重大突破,但它需要相应的图像对来进行训练,而这并不适用于所有应用。例如,如果没有为莫奈创作的每一幅画提供相应的照片,pix2pix 就无法将输入转换为莫奈绘画。
为此,Jun-Yan Zhu、Taesung Park 等人提出了 “CycleGAN”,通过组合两个条件型 GAN 和它们之间的 “循环” 来扩展 pix2pix,这一模型可以将图像转换为其他模态,而无需在训练集中看到成对图像。

今生:Transformer 和 Diffusion 之争
重大的转折发生在 2021 年,一些 “文生图” 模型纷纷降临。OpenAI 发布了 DALL·E——以 Pixar 的动画片《Wall-E》和超现实主义画家 Salvador Dali 命名。DALL·E 结合了学习将图像映射到低维标记的离散变分自动编码(dVAE)和自回归建模文本和图像标记的 Transformer 模型。输入给定的文本,DALL·E 可以预测图像标记,并在推断过程中将其解码为图像。
DALL·E 还可以将其单独学习但从未在单个生成的图像中看到的概念组合在一起。例如,在训练集中有机器人和龙的插图,没有龙形机器人。当被提示 “机器人龙” 时,模型仍可以产生对应的图像。
然而,虽然 DALL·E 可以很好地生成漫画和具有艺术风格的图像,但无法准确地生成逼真的照片。因此,OpenAI 投入了大量资源来创建改进的文生图模型——DALL·E 2。

DALL·E 2 使用 CLIP(图像文本对的数据集)文本编码器。DALL·E 2 中利用了文本描述和图像之间的关系,为 Diffusion 模型提供了一种嵌入,反映了文本输入且更适合于图像生成。与 DALL·E 相比,DALL·E 2 提高了图像的质量,并且还允许用户扩展现有图像或计算机生成的图像的背景。例如,把一些名作中的人物放置在自定义的背景之中。

不久之后,谷歌发布了名为Imagen 的文生图模型。这一模型使用 NLP 模型 T5-XXL 的预训练编码器,其嵌入被反馈送至 Diffusion 模型。因此,这一模型能够更准确地生成包含文本的图像(这是 OpenAI 的模型难以解决的问题)。
然而,在 “文生图” 领域最大的革命可能是 Stability AI 公司发布的完全开放源代码的 Stable Diffusion。Stable Diffusion 的计算效率远高于其他文生图模型,以前的文生图模型需要数百天 GPU 计算,Stable Diffusion 需要的计算量要小得多,因此资源不足的人更容易接受。它还允许用户通过图像与图像之间的转换(如将素描变成数字艺术)或绘画(在现有图像中删除或添加一些东西)来修改现有的图像。
深度学习及其图像处理应用现在处于与几年前完全不同的阶段。在上世纪初,深度神经网络能够对自然图像进行分类是开创性的。如今,这些里程碑式的模型或是采用 Transformer 或是基于 Diffusion 模型,能够基于简单的文本提示生成高度逼真和复杂的图像,使得 “文生图” 领域大放异彩,成为艺术界的一只新画笔。
“威胁” or “共生”,人类画家何去何从
AI artist 自诞生起就饱受争议,版权纠纷、输出错误信息、算法偏见等等,让“文生图”应用一次又一次站在了风口浪尖。例如,今年 1 月,三位艺术家对 Stable Diffusion 和 Midjourney 的创建者 Stability AI 和 Midjourney 以及 DreamUp 的艺术家组合平台 DeviantArt 提起了诉讼。他们声称,这些组织侵犯了 “数百万艺术家” 的权利,在 “未经原创艺术家同意” 的情况下,用从网络上抓取的 50 亿张图片来训练 AI 模型。
艺术家们大多很害怕自己会被机器人取代,因 AI 模仿其独特风格的模型而失去生计。在去年 12 月,数百名艺术家向互联网上最大的艺术社区之一 ArtStation 上传图片,表示 “对 AI 生成的图像说不”。同时,一些艺术家悲观地认为,“我们正眼睁睁地看着艺术之死展开”。围绕训练数据中使用的图像版权问题,尚处于争议之中。
当然,也不乏一些艺术家积极地拥抱 AI,将文生图模型当作自己的绘画助手,省去重复性的枯燥劳动。同时,一些艺术家将 AI 作为想象力的 “引擎”,在与类似 Midjourney 软件及社区中的用户交互中,彼此互相撕裂,产生新的、有趣的人类美学,进而溢出到真实世界。正如 Midjourney 所描述的:“AI 不是现实世界的复刻,而是人类想象力的延伸”。
目前,监管机构正在追赶 AI artist 的脚步。最近,美国版权局在一封信中表示,使用 AI 系统 Midjourney 创建的图画小说中的图像不应获得版权保护,该决定是美国法院或机构对 AI 创作的作品的版权保护范围做出的首批决定之一。另外,一些学者为保护艺术家免受文生图 DIffusion 模型的风格模仿,提出了一个允许艺术家将精心计算的扰动应用到他们的艺术中的系统—— Glaze。
一系列 “文生图” 应用允许没有编程知识的艺术家及大众使用这些强大的模型,生成极具视觉震撼的图像。“给 AI 以创造”,不论是绘画还是其他领域,这些工具可以帮助艺术家表达他们的创造力,并可能塑造艺术的未来。
AI 在艺术中的作用将取决于它的使用方式以及使用它的人的目标和价值观,重要的是要记住,这些模型的使用应该以道德和负责任的考虑为指导。
参考链接:
https://arxiv.org/abs/2302.10913
https://arxiv.org/abs/2302.04222
https://tech.cornell.edu/news/ai-vs-artist-the-future-of-creativity/
https://www.taipeitimes.com/News/biz/archives/2023/02/24/2003794928
https://www.buzzfeednews.com/article/pranavdixit/ai-art-generators-lawsuit-stable-diffusion-midjourney
https://www.theverge.com/2023/1/16/23557098/generative-ai-art-copyright-legal-lawsuit-stable-diffusion-midjourney-deviantart
https://arstechnica.com/information-technology/2023/03/ai-imager-midjourney-v5-stuns-with-photorealistic-images-and-5-fingered-hands/
涉及观点仅代表个人,与本站立场无关。本站不对内容的真实性及完整性作任何承诺。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫